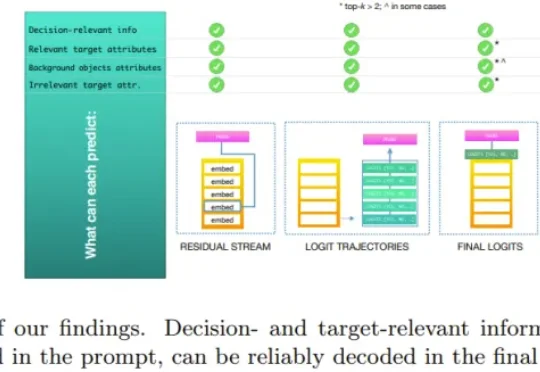
刚刚,翁荔博客又上新:通过Harness工程实现AI自我提升
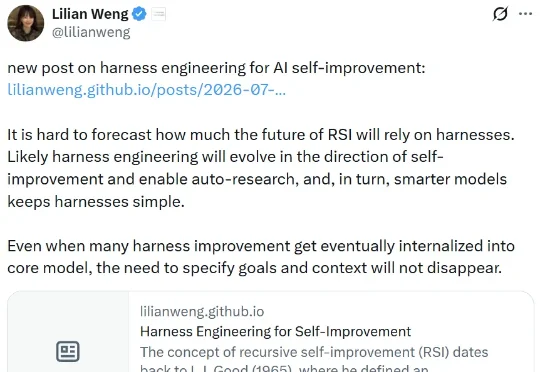
刚刚,翁荔博客又上新:通过Harness工程实现AI自我提升刚刚,翁荔(Lilian Weng)又更新博客了!距离她上一次更新《谨慎对待 Scaling Law》还不到 10 天。这一次,她书写的主题是当前大热的 Harness Engineering,聚焦的正是当下 AI 研究最前沿一个环节:当模型本身的智能已经足够强大时,真正决定它能走多远的,或许是包裹在模型外面的那层「Harness」也就是负责编排模型思考、调用工具、管理上下文、评估结果的那套系统。
来自主题: AI技术研报
9567 点击 2026-07-08 00:04